Blog post
Evolving Infrastructure: From Local Terraform to Scalable Terragrunt with Atlantis – Part 1
Infrastructure orchestration is a hotly debated topic, and the best approach isn’t always obvious. There isn’t any one-size-fits-all solution. It varies greatly based on the use cases and size of the projects in question. Learning from experience, adapting as the tech stack evolves, and aiming for maintainability are good starting points based on our experience here at Codility. In this blog post, we will share some of our journey with you on how we manage infrastructure at our scale and hope that perhaps our readers could gather some beneficial insights.
Codility currently manages over 350 individual infrastructure-as-code (IaC) projects and multiple smaller microservices deployments for its infrastructure hosted in AWS. These deployments range from development, load testing, staging, all the way to production. All of this is managed through Terraform coupled with Terragrunt.
Over the past few years, there has been significant growth in product services offered at Codility, leading to a necessity for a more flexible and autonomous management of the infrastructure. Initially, we employed pure Terraform executed locally from workstations. However, this approach became impractical as our infrastructure evolved in response to application scaling requirements. To address this challenge, we introduced Terragrunt and subsequently adopted Atlantis, an open-source tool that offered a “close-enough” GitOps solution for our Infrastructure codebase.
“Close-enough” here is specified because we do not continuously sync our main master branch to what is running in production, so in other words due to the nature of infra we can’t always guarantee master is completely representative of what is running in production nor do we want to have such enforcement to avoid the unexpected situations (API changes, provider changes, or human intervention from the console) – we aim for best effort or close-enough Gitops.
The simplified flow now resembles the following
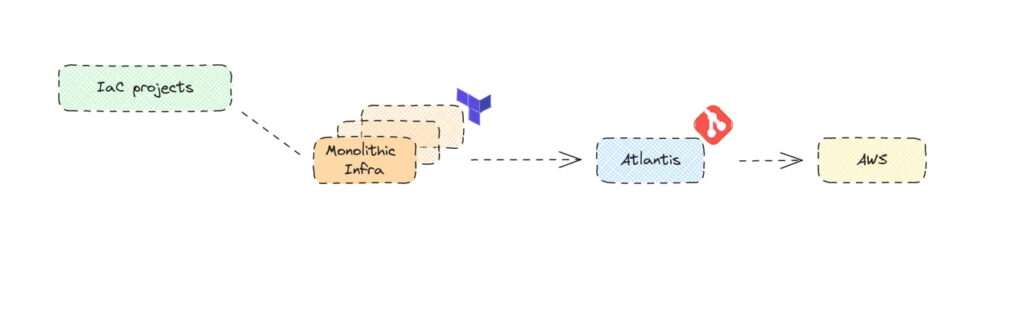
The transformation in our infrastructure at Codility over the past 2-3 years has been substantial, to say the least. This is what we will discuss in this blog post series, starting with our move to Terragrunt. But first, let’s take a brief journey into a not-too-distant past to talk about Terraform.
So why Terraform?

In 2009 when Codility was established, AWS offered Cloudformation as a cloud infrastructure orchestration solution. However, later on, Terraform was introduced in 2014. As the only cloud-agnostic kid on the block when it came to Infrastructure as Code tooling, it was quickly adopted by our pioneering DevOps engineers.
They fearlessly embarked on a perilous journey where the foundations of our first IaC code were laid as our adoption of AWS matured. However, early versions of Terraform lacked some important functionalities crucial to our needs (mentioned below). To compensate, various workarounds were implemented, inadvertently accumulating technical debt. Reflecting on it now, we can see how much the codebase has evolved since then.
As infrastructure at Codility grew, we identified certain constraints with pure Terraform that were resulting in a less-than-ideal workflow – some listed below.
- We require small modular infrastructure projects rather than everything being managed under a single Terraform state file – the goal here is maintainability (more on this later). How do we manage Terraform state for each project independently?
- How can we set up our providers so that we can have a global source of truth for our projects?
- How can we create dependencies across our Terraform projects and keep track of them?
- Setting up global configs from the top level that multiple projects can inherit from.
- And finally, how do we manage so many projects at scale, basically running Terraform across multiple projects?
In summary, it gets difficult to implement DRY (don’t repeat yourself) principles when working with pure Terraform, on many occasions we find ourselves repeating code, copying and pasting configs and hardcoding settings, creating risky situations in case of an oversight.
Infrastructure deployments should be seamless, we shouldn’t have to think about the scaffolding, rather bootstrapping and setting up workspaces should be transparent – simply initialize and start shipping.
So how did we address these?
Enter Terragrunt

It seems the above pain points were also felt by the industry at large because some smart people at gruntworks.io came up with an excellent tool called Terragrunt – The main focus was to make it easier to achieve DRY principles in Terraform IaC. Terragrunt is simply a wrapper script around Terraform that addresses all these drawbacks by leveraging Terraform CLI args populating them dynamically via a simple terragrunt.hcl file in our Terraform projects.
Although an argument can be made that adding additional configs can increase the barrier of entry and may involve additional learning as well as introduce complexity, in our experience a lot of it can be abstracted away and still manage to keep things simple for end users after initial set up.
Coming back to the point of having small modular Terraform projects; Retrospectively, Codility starting with this approach for its infrastructure has in hindsight proved to be a good bet given the limited information available at the time since splitting large projects in pursuit of smaller more manageable code could have been challenging.
Admittedly, this can be subjective, but after experiencing a 15-minute plan time for a single Terraform project that hosted the entire infrastructure – I can safely vouch for the approach of having it this way. But this does come with its challenges which Terragrunt helps address.
“The first rule of functions is that they should be small. The second rule of functions is that they should be smaller than that.”
Clean Code
So let’s discuss some details on how we address the issues we highlighted earlier by incorporating Terragrunt into our workflow
Remote State Management
Terraform still does not provide a way to configure remote state configs per project dynamically. At Codility we achieve this using a “generate” block that pulls in the state configuration from the root of the repo. It looks a little something like this:
generate "backend" {
path = "backend.tf"
if_exists = "overwrite_terragrunt"
contents = <<EOF
terraform {
backend "s3" {
encrypt = true
bucket = "<Our Global State Bucket>"
dynamodb_table = "<Our DynamoDB locking Table>"
region = "us-east-1"
key = "${replace(get_original_terragrunt_dir(), "/(.*<repo-root>/)/", "")}/terraform.state.json"
role_arn = "<Role authorized for these actions>"
}
}
EOF
}
In our IaC projects, we simply have imports set up for this resulting in a backend.tf file being generated by Terragrunt before Terraform init is run.
Each project initializes its own state file. The magic happens with the key attribute that allows us to have paths in our state s3 bucket that mimic the project paths in our repository. Hence each project has an independent state file in its own s3 path.
Provider Management
In an ideal world, every project should be running through a global provider config with pinned versions, but unfortunately, that is not always possible so we aim for the best effort.
Terragrunt allows us to have individual provider configs per project or group of projects. We can control this again by using the magical generate block in the provider config per project. We point to a provider file with the required version from the top level and Terragrunt can generate a provider.tf file before Terraform is initialized for that project.
Dependency Management
Terraform employs remote state data resources to reference an entity in a different IaC project.
This makes it difficult to track dependencies between projects when you have a lot of them creating quite a snafu – changes in one project can break another without anyone realizing it – not ideal as you may imagine. Terragrunt allows us to define explicit dependencies via the dependency blocks in the terragrunt.hcl which we can track through the terragrunt graph-dependencies command. This comes in particularly useful when running the run-all commands.
After moving to Atlantis, this has become an even more useful feature and we’ve mostly deprecated the run-all command altogether
Common HCLs
At Codility we have certain global configs placed at the root of our repo to have a common source of truth. For example, VPC configs, user-maps, endpoints, and certain hard-coded configs.
We define a global Terragrunt config in the root of our repo that imports these common HCLs, which can then be included in any project we would require them in. This way we can define global configs in a single place being imported by our projects
Terraform Apply at Scale
Imagine making a change and having to run Terraform in any number of projects greater than 1. It becomes tedious quite fast. This is where the run-all commands come in. Terragrunt can track all projects under your PWD (present working directory) by detecting the terragrunt.hcl files underneath. After which it proceeds to run the plan or apply command depending on the argument passed. The run-all command also tracks dependencies and will run Terraform in the defined sequence.
The use for this command (run-all) has greatly depreciated after we moved to Atlantis as a full Terraform continuous deployment solution where dependency mapping is done through a different custom tooling using the atlantis.yaml config
And that’s not all – let’s talk about tagging. Tagging resources is a priority at Codility, mainly for cost allocation and resource tracking among other useful aspects. Currently, we have various default tags (a feature that came to Terraform quite late) and some dynamically generated tags via Terragrunt that we use in our infrastructure. The most helpful tag for us has been the ProjectPath tag, which allows anyone to immediately know and track where a resource has been created while inspecting it from the console, and we can also attribute costs to each IaC project in our repositories. We leverage Terragrunt to have these dynamic tags set up for every project on initialization without any manual intervention, helping to keep the entire flow standardized and error-free.
So, all these factors combined made Terragrunt a great match for the engineers at Codility, resulting in a slow and steady effort to migrate to this new flow with Terragrunt.
Wait, what about SDKs?

Good question! At one point, When a certain large-scale redesign was being considered at Codility (that we will talk about in a different blog post) the possibility of migrating from Terraform HCLs to a pure programming language via an SDK came up.
The goal here was to have a common language across engineering as we moved forward with this new shift.
A large comparative analysis using various SDKs (Terraform CDK, Pulumi, AWS CDK) vs Terraform was set up and presented to developers to gauge their leanings based on the barrier to entry, usability, and other factors. Interestingly developers opted for Terraform in the end. Therefore, we decided not to switch to using SDKs and continue with Terraform as our main IaC tool at Codility.
There may have been many reasons for this, but mainly it was due to the low barrier of entry and simplicity offered by Terraform – but this of course varies and is primarily subjective.
Journey to Atlantis

Now, we still had multiple bottlenecks in our infrastructure relating to change management workflows, permissions (IAM), delegation, and local development (“it works on my machine”). Furthermore, despite our best efforts, we continued to encounter projects that were out of sync with production from time to time. In short, our velocity was taking a significant hit. Engineering time was being spent unblocking engineers rather than enabling them to deliver faster.
This now brings us to Atlantis. We’ve made several references to Atlantis and we should talk about why this tool was introduced to our infrastructure in more detail, but this is a full topic in itself that is deserving of its own blog post.
So we recommend staying tuned for part two where we go over the capabilities of Atlantis, the reason that led to us adopting it at scale, and how we use it at Codility.